Viewstamped replication(VR) is a state machine replication algorithm used to build highly available systems that continue to operate correctly even in presence of node failures and network partitions.
It replicates change in state from one node to all other nodes over network.
It differs from Paxos in that it is a replication protocol rather than a consensus protocol: it uses consensus, with a protocol very similar to Paxos, as part of supporting a replicated state machine
VR provides linearizability and it can sustain failure of f out of 2f+1 replicas.
Overview
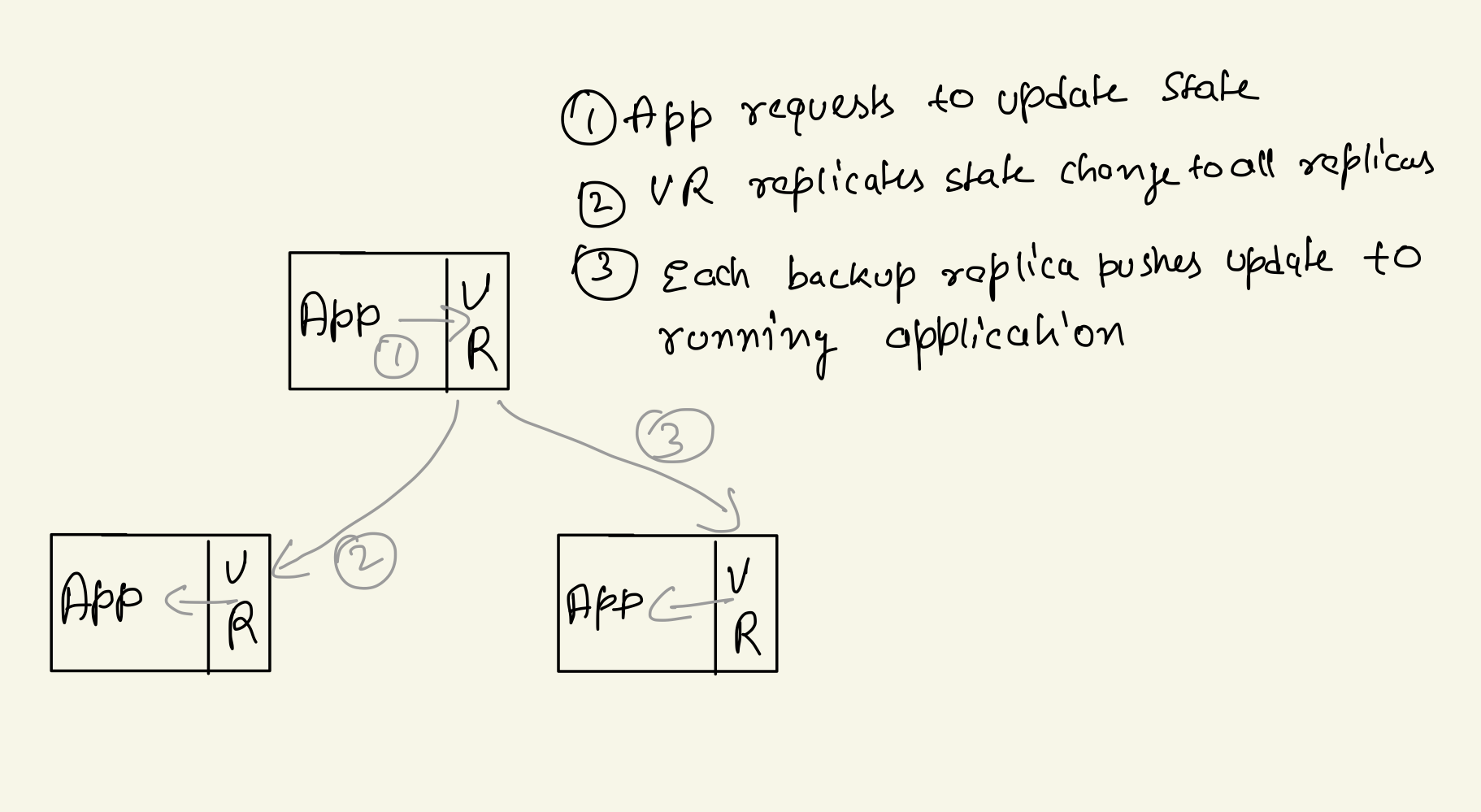
VR has two types of nodes Primary and Backup. Primary receives all client requests in order and then replicates them to backup replicas. All Backup replicas simply accepts requests from primary in order.
If anytime primary crashes or is unreachable over network a new primary is elected by a view change process. View change creates a new view with always increasing view number. View Change ensures that all requests committed(acknowledged) by VR must survive a view change.
This requirement is met by having the primary wait until at least f + 1 replicas (including it-self) know about a client request before executing it, and by initializing the state of a new view by consulting at least f + 1 replicas. Thus each request is known to a quorum and the new view starts from a quorum.
When a failed replica comes back online it catches up with other replicas and rejoins replication.
VR uses three sub-protocols that work together to ensure correctness:
- Normal case processing of user requests.
- View changes to select a new primary.
- Recovery of a failed replica so that it can rejoin the group.
Working
Normal Operation
Nodes are in normal state in absence of any faults and process incoming requests. All replicas participating must belong to same view (same view number) if any receiver is different view then:
- If Sender is behind it will drop incoming message
- If Sender is ahead replica performs a state transfer and update it’s state to latest.
Protocol:
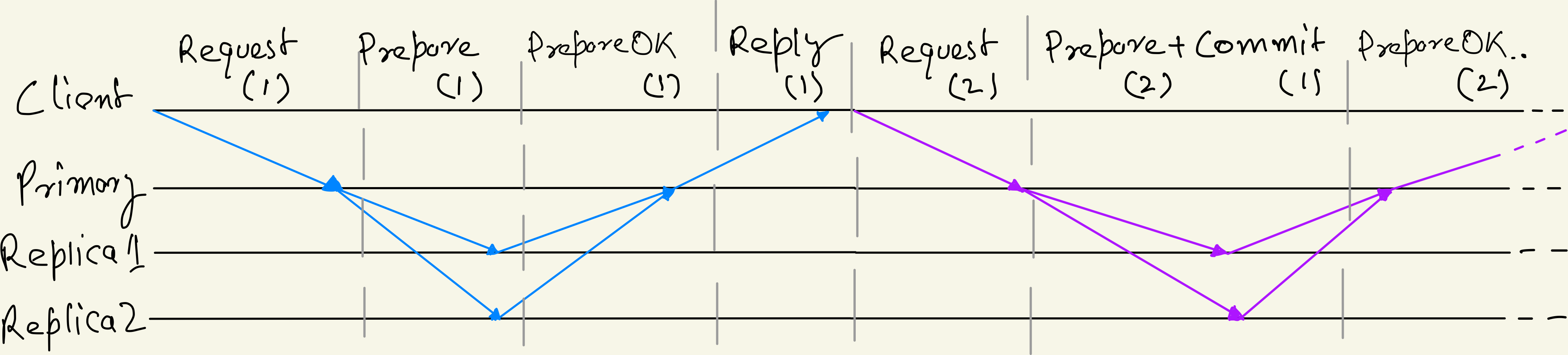
- Primary sends
Preparemessage to all (2f+1) replicas and wait till it getsPrepareOKresponse from f+1 (including itself) replicas. - When Backup receives
Preparemessage it adds it to its log, increases op-number and sends backPrepareOKto primary. - After receiving f+1
PrepareOKPrimary considers this operation as Committed, increases its commit number and replies to the client. Note that only primary considers this operation as committed whereas other replicas still only consider it as Prepared. - When then next request is received, primary piggybacks the
Commitof last message withPreparemessage. If next there is no next message primary timeouts and sends only the Commit message to replicas at regular intervals. - When Backup receives
Commitmessages it notifies the running Application or client on the node of the committed operation.
View Change
Backups monitor the primary: they expect to hear from it regularly. Normally the primary is sending PREPARE messages, but if it is idle (due to no requests) it sends COMMIT messages instead. If a timeout expires without a communication from the primary, the replicas carry out a view change to switch to a new primary
There is no leader election as such to choose a new primary. The replicas are numbered based on their IP addresses: the replica with the smallest IP address is replica 1. The primary is chosen round-robin, starting with replica 1, as the system moves to new views.
Correctness Condition: All Committed operations must survive view change and should be present in log of new primary.
Operations are committed only after primary receives f+1 PrepareOK messages from replicas, that means even if primary fails, the new proposed primary would know about this operation as it will also query f+1 replica and operation will be present in log of at-least one of these replicas because of Quorum intersection property.
Protocol
- If a replica it has not received COMMIT or PREPARE message in a while and timeouts, then it starts view changes by advancing it’s
view numbersetting its status toview-changeand sendsStartViewChangemessage to all other replicas. - When the replica receives
StartViewChangemessages for its view-number from f other replicas, it sends aDoViewChangemessage to the node that will be the primary in the new view. - When the new primary receives f + 1
DoViewChangemessages from different replicas (including itself), it sets its view-number to that in the messages and selects the new log , selects It setsop-numberandcommit-numberto that of largest such number it received in theDoViewChangemessages from latest normal view, changes its status to normal, and informs the other replicas of the completion of the view change by sendingStartView - The new primary starts accepting client requests. It also executes (in order) any committed operations that it hadn’t executed previously, and sends the replies to the clients.
- When other replicas receive the
StartViewmessage, they replace their log with the one in the message (now all replicas and primary has same logs), set their op-number to that of the latest entry in the log, set their view-number to the view number in the message, change their status to normal . If there are non-committed operations in the log, they send aPrepareOKmessage to the primary (and primary would receive min f+1 suchPrepareOKmessages from all replicas as all of them have same log, the prepared message will be committed and reply will be sent to client by primary). Then they execute all operations known to be committed that they haven’t executed previously.
A view change may not succeed, e.g., because the new primary fails or is network partitioned. In this case the replicas will start a new view change, with yet another primary.
Correctness In Faulty Scenarios
Here we examine what happens when primary fails in different scenarios. A primary failure will always be fallowed by a view change which will elect new leader and bring state back to normal.
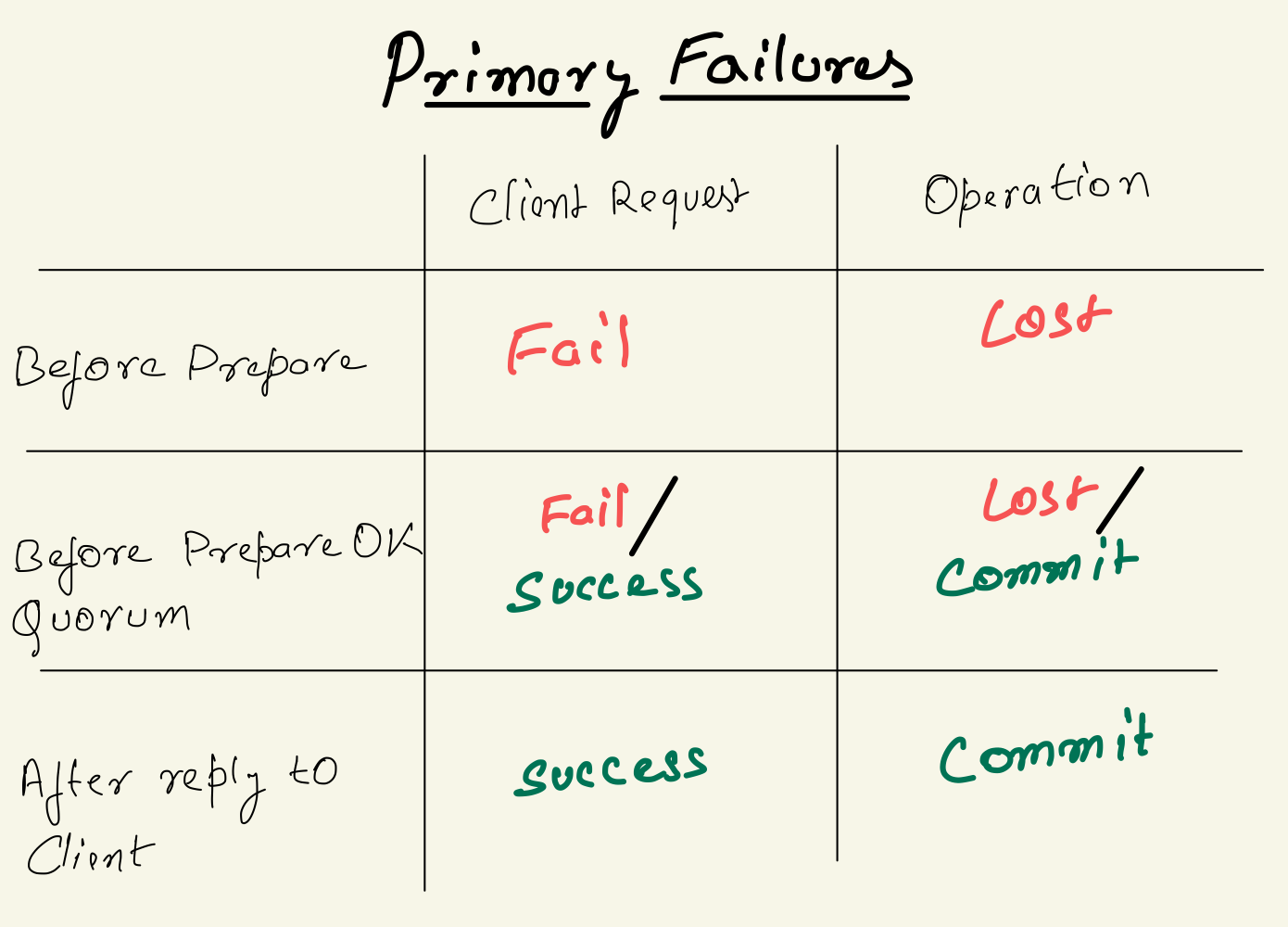
1. Primary fails before sending Prepare message to any replica:
No replica received Prepare message and has no record of operation in its logs and no reply to client as primary failed.
2. Primary fails after sending Prepare message to replicas but before receiving PrepareOK from f+1 replicas:
This Operation was never committed by primary but any number of replicas could have received Prepare message and would have prepared the message in its logs.
There could be multiple factors determining weather this message will survive a view change or not.
a. If number of replicas with prepared message >= f +1: If no. of replicas with prepared Message is >= f+1 (quorum), the operation will always survive view change as prepared message will always be known to nodes participating in view change due to quorum intersection property. This operation will later be committed after view change.
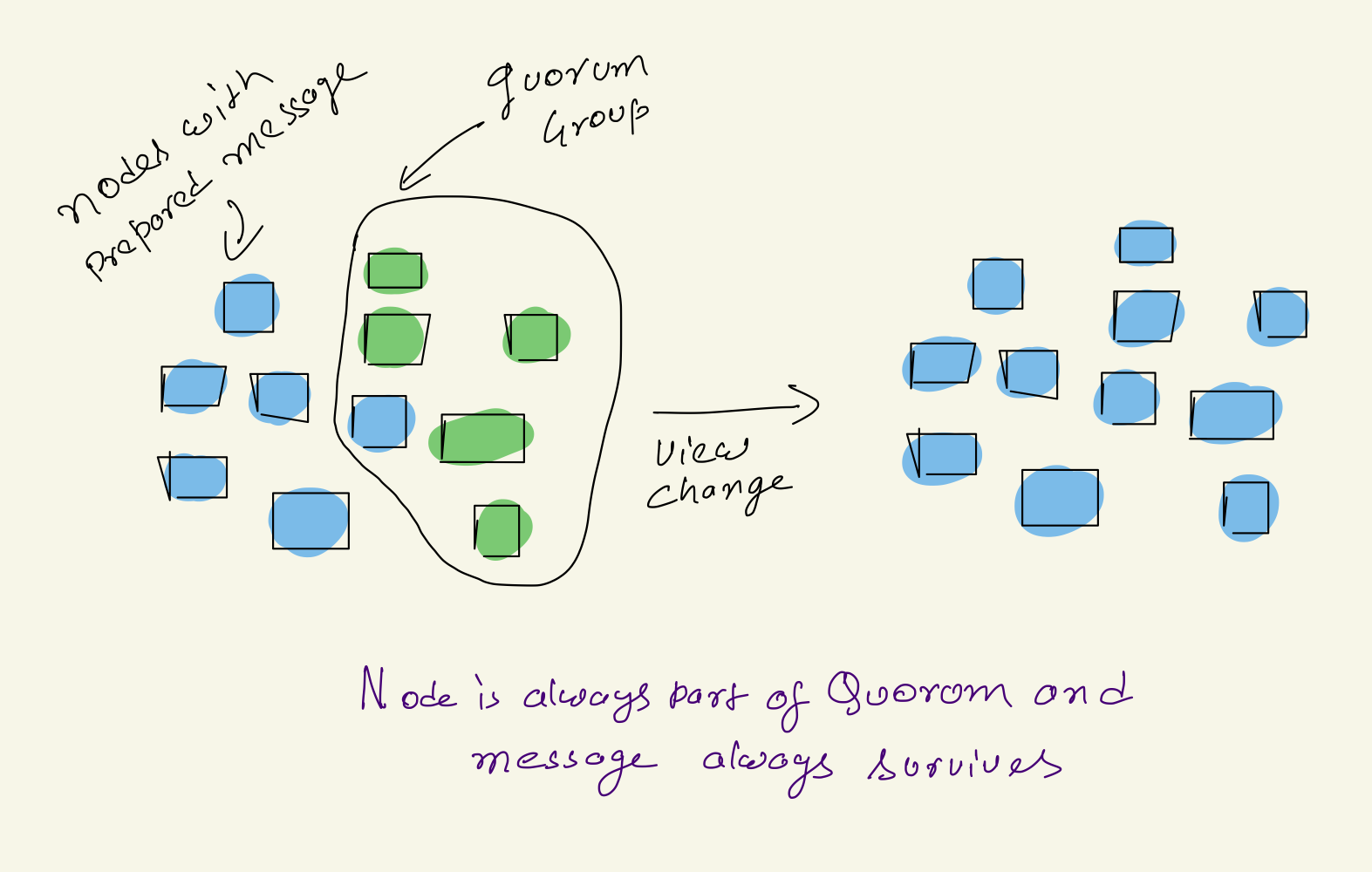
b. If number of replicas with prepared message < f +1:
If number of nodes with prepared message is < f+1, not enough to apply quorum intersection property. During View Change quorum nodes with Prepared messages may or may not take part in in quorum depending or various reasons like node failure or network partition.
- If nodes with message do not take part in Quorum the message will be lost.
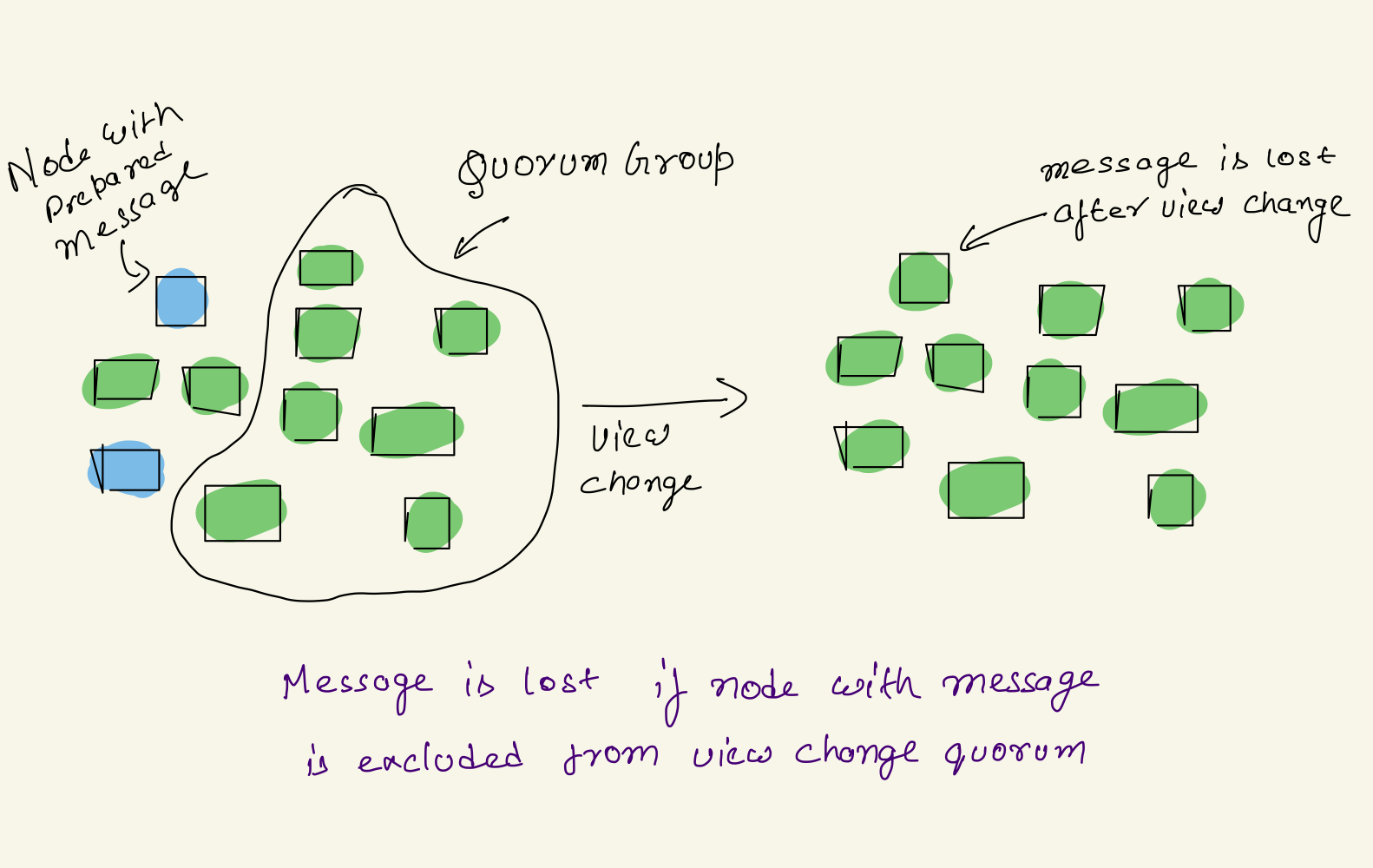
- If these nodes are part of quorum, then message will survive view change
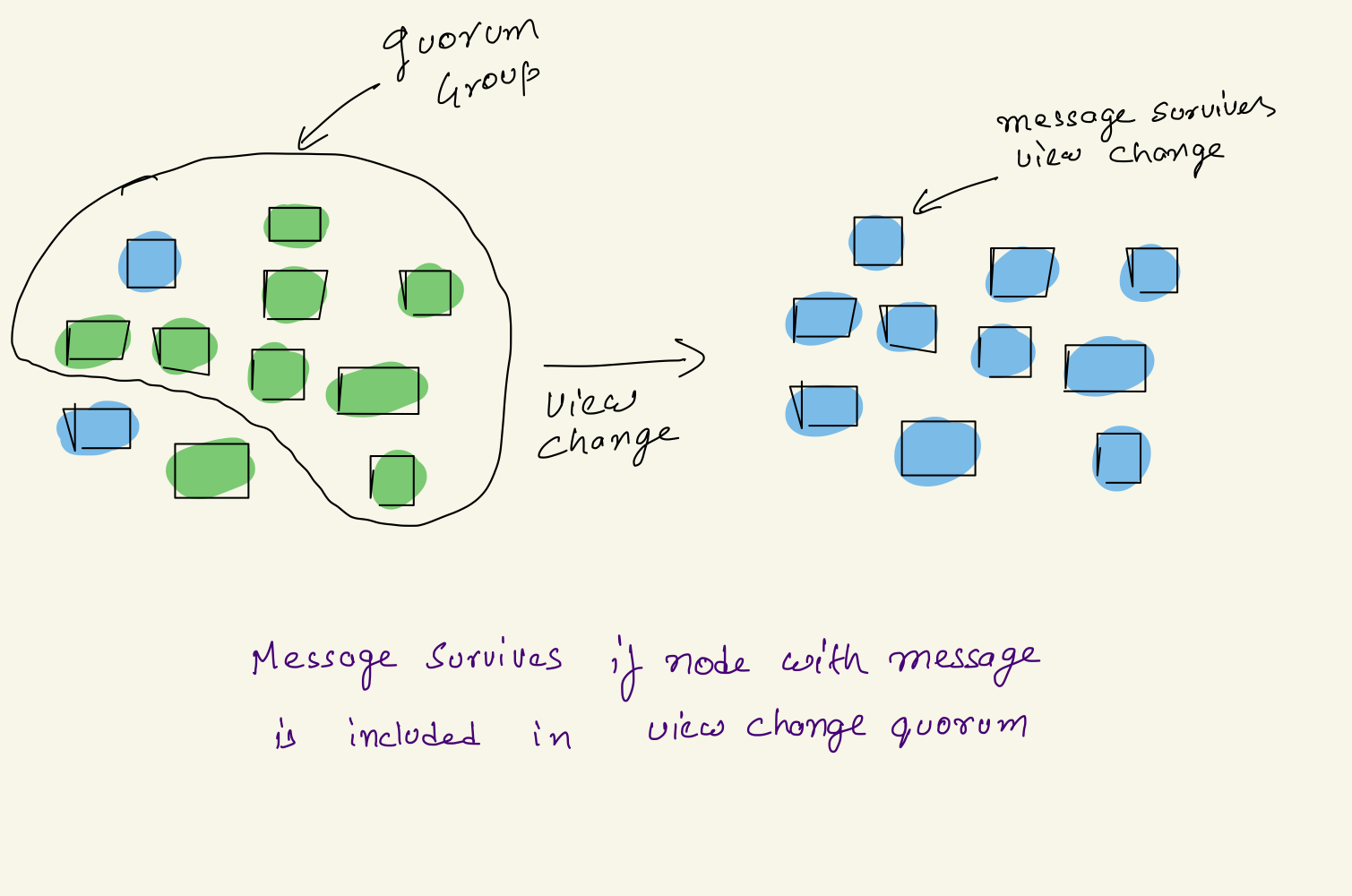
3. Primary fails after sending reply message to client:
Primary only sends reply to client when it has received PrepareOK from f+1 replicas and committed the message, if f+1 replicas have the Prepared message then it is guaranteed to survive view change same as condition 2.a.
Recovery Of Failed Nodes
In VR, nodes do not write to disk while normal operation as it makes operation expensive, instead it relies on other nodes to sync its state. When a node recovers from failure it does not go to normal state but goes to recovery state and retrieves logs from other nodes using recovery protocol over network.
If all nodes with a committed message fails at same time, then that message would be lost as no other nodes knows about it. VR assumes that its highly unlikely that all such replicas fail at same time.
Protocol
- The recovering replica, i, sends a RECOVERY message to all other replicas, with a nonce (random-time-based value).
- A replica j replies to a RECOVERY message only when its status is normal. In this case the replica sends a RECOVERYRESPONSE message to the recovering replica, with the nonce received in the RECOVERY message.
- The recovering replica waits to receive at least f + 1 RECOVERYRESPONSE messages from different replicas, all containing the nonce it sent in its RE- COVERY message, including one from the primary of the latest view it learns of in these messages. Then it updates its state using the information from the primary, changes its status to normal, and the recovery protocol is complete.
The protocol uses the nonce to ensure that the recovering replica accepts only RECOVERYRESPONSE messages that are for this recovery and not an earlier one.
Practical Optimizations
Efficient Recovery
VR does not need disk while performing any operation and during recovery it needs to transfer complete state from another which can be time taking when state is large. To optimize data transfer during recovery nodes can checkpoint their state to disk at regular intervals with checkpoint number (op-number)
When a node recovers, it first obtains the application state from another replica. To make this efficient, the application maintains a Merkle tree over the pages in the snapshot. The recovering node uses the Merkle tree to determine which pages to fetch; it only needs to fetch those that differ from their counterpart at the other replica.
Batching
Use of batching to reduce the over- head of running the protocol. Rather than running the protocol each time a request arrives, the primary collects a bunch of requests and then runs the protocol for all of them at once.
Optimizing Reads On Application
Read operation cause no change in application state so need not to go through Viewstamp Replication systems but only can be answered by running itself.
Having the application running on primary perform read requests unilaterally could lead to the read returning a result based on an old state. This can happen if the request goes to an old primary that is not aware that a view change has occurred.
To avoid stale reads application need to query quorum of f+1 replicas and find latest state.
Reads at the Primary
To optimize reads and prevent a primary returning results based on stale data, leases are used. The primary processes reads unilaterally only if it holds valid leases from f other replicas, and a new view will start only after leases at f + 1 participants in the view change protocol expire. This ensures that the new view starts after the old primary has stopped replying to read requests, assuming clocks rates are loosely synchronized.
References
http://pmg.csail.mit.edu/papers/vr.pdf
http://pmg.csail.mit.edu/papers/vr-revisited.pdf
https://blog.acolyer.org/2015/03/06/viewstamped-replication-revisited/